
This post focuses on the intake of two main plant foods, namely wheat flour and rice intake, and their relationships with mortality from all cardiovascular diseases. After many exploratory multivariate analyses, wheat flour and rice emerged as the plant foods with the strongest associations with mortality from all cardiovascular diseases. Moreover, wheat flour and rice have a strong and inverse relationship with each other, which suggests a “consumption divide”. Since the data is from China in the late 1980s, it is likely that consumption of wheat flour is even higher now. As you’ll see, this picture is alarming.
The main model and results
All of the results reported here are from analyses conducted using WarpPLS (). Below is the model with the main results of the analyses. (Click on it to enlarge. Use the "CRTL" and "+" keys to zoom in, and CRTL" and "-" to zoom out.) The arrows explore associations between variables, which are shown within ovals. The meaning of each variable is the following: SexM1F2 = sex, with 1 assigned to males and 2 to females; MVASC = mortality from all cardiovascular diseases (ages 35-69); TKCAL = total calorie intake per day; WHTFLOUR = wheat flour intake (g/day); and RICE = and rice intake (g/day).
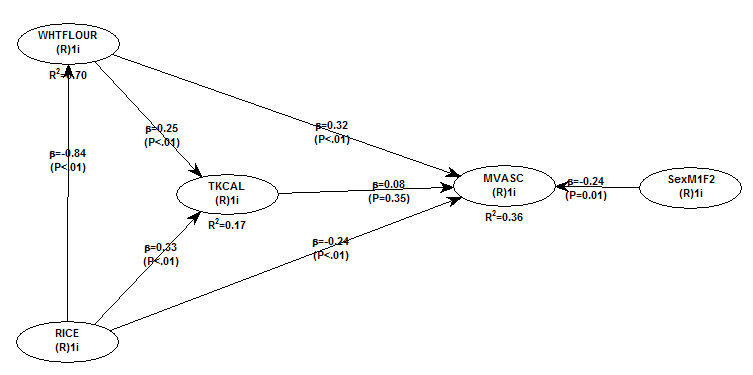
The variables to the left of MVASC are the main predictors of interest in the model. The one to the right is a control variable – SexM1F2. The path coefficients (indicated as beta coefficients) reflect the strength of the relationships. A negative beta means that the relationship is negative; i.e., an increase in a variable is associated with a decrease in the variable that it points to. The P values indicate the statistical significance of the relationship; a P lower than 0.05 generally means a significant relationship (95 percent or higher likelihood that the relationship is “real”).
In summary, the model above seems to be telling us that:
- As rice intake increases, wheat flour intake decreases significantly (beta=-0.84; P<0.01). This relationship would be the same if the arrow pointed in the opposite direction. It suggests that there is a sharp divide between rice-consuming and wheat flour-consuming regions.
- As wheat flour intake increases, mortality from all cardiovascular diseases increases significantly (beta=0.32; P<0.01). This is after controlling for the effects of rice and total calorie intake. That is, wheat flour seems to have some inherent properties that make it bad for one’s health, even if one doesn’t consume that many calories.
- As rice intake increases, mortality from all cardiovascular diseases decreases significantly (beta=-0.24; P<0.01). This is after controlling for the effects of wheat flour and total calorie intake. That is, this effect is not entirely due to rice being consumed in place of wheat flour. Still, as you’ll see later in this post, this relationship is nonlinear. Excessive rice intake does not seem to be very good for one’s health either.
- Increases in wheat flour and rice intake are significantly associated with increases in total calorie intake (betas=0.25, 0.33; P<0.01). This may be due to wheat flour and rice intake: (a) being themselves, in terms of their own caloric content, main contributors to the total calorie intake; or (b) causing an increase in calorie intake from other sources. The former is more likely, given the effect below.
- The effect of total calorie intake on mortality from all cardiovascular diseases is insignificant when we control for the effects of rice and wheat flour intakes (beta=0.08; P=0.35). This suggests that neither wheat flour nor rice exerts an effect on mortality from all cardiovascular diseases by increasing total calorie intake from other food sources.
- Being female is significantly associated with a reduction in mortality from all cardiovascular diseases (beta=-0.24; P=0.01). This is to be expected. In other words, men are women with a few design flaws, so to speak. (This situation reverses itself a bit after menopause.)
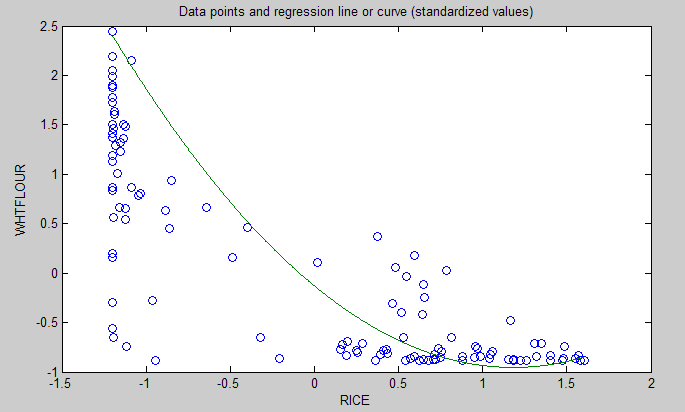
Wheat flour displaces rice
The graph below shows the shape of the association between wheat flour intake (WHTFLOUR) and rice intake (RICE). The values are provided in standardized format; e.g., 0 is the mean (a.k.a. average), 1 is one standard deviation above the mean, and so on. The curve is the best-fitting U curve obtained by the software. It actually has the shape of an exponential decay curve, which can be seen as a section of a U curve. This suggests that wheat flour consumption has strongly displaced rice consumption in several regions in China, and also that wherever rice consumption is high wheat flour consumption tends to be low.
As wheat flour intake goes up, so does cardiovascular disease mortality
The graphs below show the shapes of the association between wheat flour intake (WHTFLOUR) and mortality from all cardiovascular diseases (MVASC). In the first graph, the values are provided in standardized format; e.g., 0 is the mean (or average), 1 is one standard deviation above the mean, and so on. In the second graph, the values are provided in unstandardized format and organized in terciles (each of three equal intervals).


The curve in the first graph is the best-fitting U curve obtained by the software. It is a quasi-linear relationship. The higher the consumption of wheat flour in a county, the higher seems to be the mortality from all cardiovascular diseases. The second graph suggests that mortality in the third tercile, which represents a consumption of wheat flour of 501 to 751 g/day (a lot!), is 69 percent higher than mortality in the first tercile (0 to 251 g/day).
Rice seems to be protective, as long as intake is not too high
The graphs below show the shapes of the association between rice intake (RICE) and mortality from all cardiovascular diseases (MVASC). In the first graph, the values are provided in standardized format. In the second graph, the values are provided in unstandardized format and organized in terciles.


Here the relationship is more complex. The lowest mortality is clearly in the second tercile (206 to 412 g/day). There is a lot of variation in the first tercile, as suggested by the first graph with the U curve. (Remember, as rice intake goes down, wheat flour intake tends to go up.) The U curve here looks similar to the exponential decay curve shown earlier in the post, for the relationship between rice and wheat flour intake.
In fact, the shape of the association between rice intake and mortality from all cardiovascular diseases looks a bit like an “echo” of the shape of the relationship between rice and wheat flour intake. Here is what is creepy. This echo looks somewhat like the first curve (between rice and wheat flour intake), but with wheat flour intake replaced by “death” (i.e., mortality from all cardiovascular diseases).
What does this all mean?
- Wheat flour displacing rice does not look like a good thing. Wheat flour intake seems to have strongly displaced rice intake in the counties where it is heavily consumed. Generally speaking, that does not seem to have been a good thing. It looks like this is generally associated with increased mortality from all cardiovascular diseases.
- High glycemic index food consumption does not seem to be the problem here. Wheat flour and rice have very similar glycemic indices (but generally not glycemic loads; see below). Both lead to blood glucose and insulin spikes. Yet, rice consumption seems protective when it is not excessive. This is true in part (but not entirely) because it largely displaces wheat flour. Moreover, neither rice nor wheat flour consumption seems to be significantly associated with cardiovascular disease via an increase in total calorie consumption. This is a bit of a blow to the theory that high glycemic carbohydrates necessarily cause obesity, diabetes, and eventually cardiovascular disease.
- The problem with wheat flour is … hard to pinpoint, based on the results summarized here. Maybe it is the fact that it is an ultra-refined carbohydrate-rich food; less refined forms of wheat could be healthier. In fact, the glycemic loads of less refined carbohydrate-rich foods tend to be much lower than those of more refined ones (). (Also, boiled brown rice has a glycemic load that is about three times lower than that of whole wheat bread; whereas the glycemic indices are about the same.) Maybe the problem is wheat flour's gluten content. Maybe it is a combination of various factors (), including these.
Notes
- The path coefficients (indicated as beta coefficients) reflect the strength of the relationships; they are a bit like standard univariate (or Pearson) correlation coefficients, except that they take into consideration multivariate relationships (they control for competing effects on each variable). Whenever nonlinear relationships were modeled, the path coefficients were automatically corrected by the software to account for nonlinearity.
- The software used here identifies non-cyclical and mono-cyclical relationships such as logarithmic, exponential, and hyperbolic decay relationships. Once a relationship is identified, data values are corrected and coefficients calculated. This is not the same as log-transforming data prior to analysis, which is widely used but only works if the underlying relationship is logarithmic. Otherwise, log-transforming data may distort the relationship even more than assuming that it is linear, which is what is done by most statistical software tools.
- The R-squared values reflect the percentage of explained variance for certain variables; the higher they are, the better the model fit with the data. In complex and multi-factorial phenomena such as health-related phenomena, many would consider an R-squared of 0.20 as acceptable. Still, such an R-squared would mean that 80 percent of the variance for a particularly variable is unexplained by the data.
- The P values have been calculated using a nonparametric technique, a form of resampling called jackknifing, which does not require the assumption that the data is normally distributed to be met. This and other related techniques also tend to yield more reliable results for small samples, and samples with outliers (as long as the outliers are “good” data, and are not the result of measurement error).
- Only two data points per county were used (for males and females). This increased the sample size of the dataset without artificially reducing variance, which is desirable since the dataset is relatively small. This also allowed for the test of commonsense assumptions (e.g., the protective effects of being female), which is always a good idea in a complex analysis because violation of commonsense assumptions may suggest data collection or analysis error. On the other hand, it required the inclusion of a sex variable as a control variable in the analysis, which is no big deal.
- Since all the data was collected around the same time (late 1980s), this analysis assumes a somewhat static pattern of consumption of rice and wheat flour. In other words, let us assume that variations in consumption of a particular food do lead to variations in mortality. Still, that effect will typically take years to manifest itself. This is a major limitation of this dataset and any related analyses.
- Mortality from schistosomiasis infection (MSCHIST) does not confound the results presented here. Only counties where no deaths from schistosomiasis infection were reported have been included in this analysis. Mortality from all cardiovascular diseases (MVASC) was measured using the variable M059 ALLVASCc (ages 35-69).










